
As i have explained in the previous blog post i wanted – in light of the situation of name tagging in OpenStreetMap having been stuck for many years now – to try presenting a proof of concept how a solution to this could look like that both demonstrates the practical benefits and that shows a transit path from the status quo towards more elegant mapping concepts while maintaining the paradigm of map design to support, but not actively steer.
The difficulty with doing that is that – as i have discussed many times already now – the tools available for rule based map design have largely been stuck for even longer than name tagging in OSM. Commercial map producers have for the last ten years essentially a hundred percent focused on creating maps for the language needs and preferences of their target customers – which is a completely different problem than to create a map which shows the locally used names everywhere on the planet.
Beyond that, the whole domain of label and symbol rendering in OSM-Carto is also in a precariously unmaintained state for many years now. So when i decided to work on this i needed to do quite a lot of yak shaving first as prerequisite of implementing the name rendering in a way that is not too awkward (and in particular: To avoid the need to make tons of changes in the essentially non-maintainable and fairly chaotic amenity-points.mss file). Many of the changes made (in particular the modularization of the layer definition and the re-design of the POI symbol and label rendering with auto-generated SQL and MSS code) deserve a discussion on their own. In summary, all of these changes are highly experimental, even more so than most previous changes in the Alternative Colors style. Much of the design is code wise not very elegant. As said: this is meant to be a proof of concept, not a ready-to-use product.
As i have explained in the previous blog post, the situation with mapping of local names in OSM is severely stuck. So the usual approach of OSM-Carto to very directly depict what mappers map is not going to work because the only thing to do then would be to universally stop rendering labels based on the name tag – which is evidently not a very constructive approach. There is the possibility though to keep rendering the main use case of single names in the name tag but to selectively stop rendering the more problematic variants. This is the approach i have taken here.
One development that helped a lot with doing this is a tagging idea that was suggested a few years back as a solution for problems of rendering a map for a specific language audience (the labeling strategy of commercial maps, labeling for a specific target map viewer rather than displaying the local name everywhere) that has gained some traction meanwhile – the default_language tag. Originally meant to record the language that is the most likely language in the area (hence maintaining the illusion of there being a single local name for everything) it was recently modified by mappers in a way that is fairly close to what i suggested back in 2017. I will get to how i use this information in the following.
Interpreting multilingual compound names
Let’s first start with explaining the new name rendering logic in the hypothetical case of an English-German multilingual region:
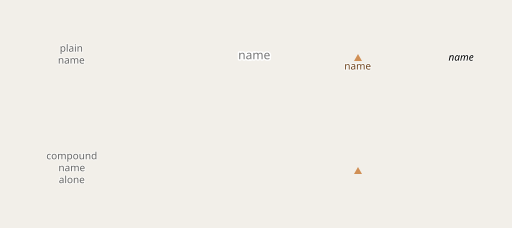
First of all plain single names in the name tag remain being rendered as is. The primary difference (shown in the second line) is that compound names in the name tag alone (without any other name tags containing the individual names) are not shown any more. Compound names are here defined as names that:
- contain one of ‘
/ ',' - 'or';'(slash/dash with spaces around or semicolon) - contain words (separated by spaces) composed of characters from different scripts
And as you can see below you can have literal semicolons in names by escaping them with double semicolons:

Remember that we are in a hypothetical English-German multilingual region – but since we have no way to know that so far, it is clear that name:en and name:de are not affecting the name rendering, a single name in the name tag has priority.
If, however, components of the compound name tag are separately tagged in name:en or name:de (or any other name:<lang> for that matter) – things change:

As you can see, i only render those parts of a compound name that can also be found in the individual name tags.
What you can also see is that the separator used in rendering is a line break. This is for horizontal point labels, for line labels (like on roads, not shown so far) i use ' - '.
Single language compound names
But what about compound names with components from the same language? Here the logic is very similar, just that the individual names tags interpreted are official_name, loc_name, alt_name and name:right/name:left. name:right/name:left are even shown when there is no name tag.

This rendering logic is not directly supported by established mapping practice, it is an extrapolation of the consensus we have on multilingual names. Because there is – based on established mapping practice – no reliable way to distinguish between compound labels of a single language and multilingual compound labels, the logic has to be the same in both cases. This could change in the future through interpretation of default_language – which i am going to discuss in the following.
Using default_language
So far what i have shown is simply how map rendering can enforce the established convention that the components of a compound name tag should be also separately recorded in individual tags. This neither solves the han unification problem nor does it provide a path towards a substantially more sustainable mapping practice for name mapping. This is done by interpreting the default_language tag.
default_language was originally suggested as a tag to record the most likely language of the name tag within an administrative unit. It is, however, predominantly and increasingly used for tagging the primary or most common language or languages of an administrative unit. I use it in both meanings. There does not appear to be a clear consensus on the delimiter in that tag in case of multiple languages yet, i allow the same delimiters as for the name tag.
As the tag is applied to administrative units and not to individual features, you need to preprocess the administrative boundary data to use that efficiently in map rendering. I have a proof-of-concept process for that as well but have not published it so far because it is very preliminary – you can, however, download the results.
In addition to the default_language tags of the administrative divisions as mapped, de-duplicated in overlaps with priority on the higher admin_level, i also modify the language information in Chinese speaking areas to provide information about simplified vs. traditional Chinese (more on that later):
UPDATE boundaries SET default_language = 'zh-Hans,zh' WHERE default_language = 'zh';
UPDATE boundaries SET default_language = 'zh-Hant,zh' WHERE country = 'tw';
UPDATE boundaries SET default_language = 'zh-Hant,zh' WHERE country = 'hk' AND admin_level = 3;
UPDATE boundaries SET default_language = 'zh-Hant,zh' WHERE country = 'mo' AND admin_level = 3;
Here is how this default_language attribute is interpreted in case of our hypothetical English-German multilingual region:

As you can see the default_language value is, in this case, used for two purposes:
- to decide on the order of names in rendering.
- to render
name:<lang>for lang indefault_languagein cases if there is no name tag.
How to write things is as important as what to write
In addition – and this might actually be the more significant part of the change because it affects a large number of people not only in multilingual regions – i use the default_language information to select different fonts in different parts of the world to address the Han unification problem.
A big disclaimer here: I am no expert in typography of any of the scripts where i vary the font based on language. If the style of script actually represents local practice in these regions and if the change as implemented here leads to better usability of the map is not really clear to me. This is not ultimately what this is about though. What i try to show is the principal feasibility of adjusting the fonts based on language.
Here is how it looks like for Chinese, Japanese and Korean (CJK). The sample towns chosen (Chuanchang and Mifune) might not be the best to demonstrate this – but they show the principle. Because the difference might be difficult to properly see at this size you can click on the sample to get a double resolution version.

Especially the following things can be observed here:
- The default rendering is Simplified Chinese. This differs from OSM-Carto, which defaults to Japanese. However, based on number of people affected, Simplified Chinese is clearly the more logical choice. Note the default is only relevant for parts of the world where
default_languagedoes not change the script style (i.e. countries outside the CJK regions). - For single names in the name tag like here the
default_languageoverrides the individual name tag matching to determine the language. Otherwise Chuanchang would not be rendered in the Japanese variant withdefault_language=jabecause there is noname:ja. - The tagging of
name:zh,name:zh-Hansandname:zh-Hantis redundant in this case because all variants are identical.
Some real world tagging examples from outside the CJK domain:
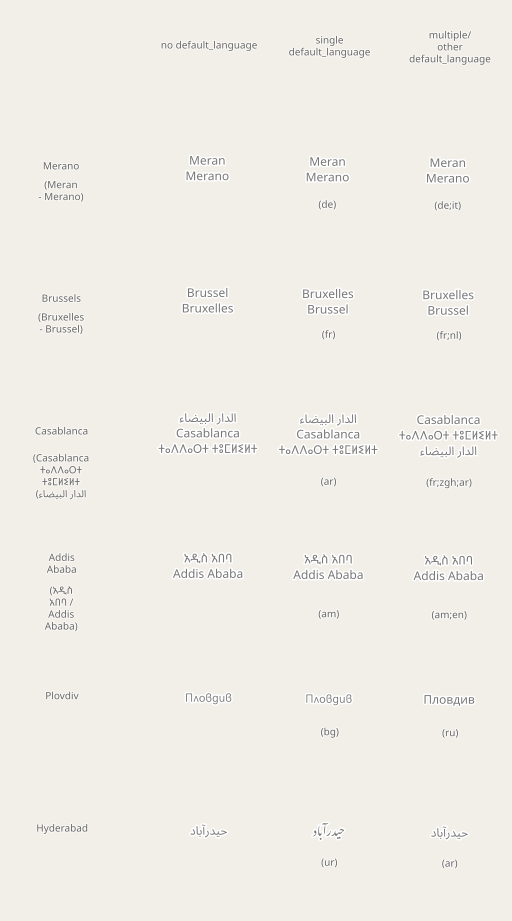
Note in particular the reason why it is Brussel – Bruxelles without default_language is because the order in rendering is alphabetical w.r.t. language code based on matching with the individual names, and Brussel matches name:af here, which comes before name:fr. default_language helps resolving such ambiguities.
Some comments on the implementation:
Because i implemented this change in name rendering in combination with various other changes of significant impact on the style overall, it is a bit difficult probably to understand by looking at the code changes. The main part of the functionality is implemented in a number of SQL functions you can find in sql/names.sql. In the queries of the style layers this is used like:
(SELECT
way,
name_label[1] AS name,
name_label[3] AS font,
...
FROM
(SELECT
way,
carto_label_name(way, name, tags, E'\n') AS name_label,
...
FROM planet_osm_polygon
WHERE ...) AS _
WHERE name_label[1] IS NOT NULL
) AS layer_name
And on the CartoCSS level you then use something like:
#layer {
[zoom >= 14] {
text-name: "[name]";
text-face-name: @book-fonts;
[font = 'jp'] { text-face-name: @book-fonts-jp; }
[font = 'tc'] { text-face-name: @book-fonts-tc; }
[font = 'kr'] { text-face-name: @book-fonts-kr; }
[font = 'ur'] { text-face-name: @book-fonts-ur; }
[font = 'bg'] { text-face-name: @book-fonts-bg; }
...
}
}
Because of Mapnik’s particularities in interpreting fonts (newer versions of Mapnik seem to try to be over-clever and guess the language of a string and then select font locl accordingly) the only way to actually control the script type is to use font files which only contain a single set of glyphs and not allow choosing one of several with the locl mechanism. For Noto Sans CJK these single language fonts are readily available from Google, for Bulgarian Cyrillic i had to modify the fonts used (Acari Sans) and remove the Russian Cyrillic variant. See get-fonts.sh for details.
Some potential questions:
That was just a very quick look over this change in name rendering, skipping a lot of details. There are a number of issues i anticipate readers to see that i will try to discuss briefly here:
The name interpretation logic is complicated, doesn’t that clash with the goal to be intuitively understandable for mappers?
Yes, that is a valid point. Keep in mind, however, that a very simplistic interpretation of name tagging is what got us into the current situation in the first place. The world of geographic names is complicated and this can only be properly dealt with if mappers and data users alike embrace the complexity.
Doesn’t this actively steer mappers into changing their mapping practice?
IMO much less than the current practice of plainly rendering the name tag no matter what. The overall idea of this change is to pick up on the few things where there mappers seem to have a clear consensus and to do the necessary extrapolations/extensions of that to create a viable and consistent rendering logic that supports mappers in a consistent mapping practice based on their own consensus decisions. And the rendering logic is deliberately designed to allow adapting to future changes in mapping practice. If default_language, for example, is in the future more widely adopted, it can be considered to allow it overriding the name tag (like for example if a language in default_language is tagged individually as name:<lang> but not as part of name, or to prefer name:<default_language> over a single name in the name tag). Some decisions that might be considered steering (like allowing default_language on the feature level) are currently in the code mainly to facilitate easier testing.
Wouldn’t this require all data users to use a similarly complex logic.
No, the good things about this approach is that data users satisfied with the status quo can continue to interpret the name tag as a label tag. The quality of the name tag might over time further degrade, but this is likely to happen anyway. And if mappers embrace the possibilities this approach offers for more cleanly structured name tagging (in whatever specific form they decide to do so), it will likely become much easier to semantically interpret the name data than it is right now.
Isn’t the logic of splitting compound name tags awfully complicated? Wouldn’t it be much easier to just standardize on semicolon as separator?
I don’t think there is a huge difference between supporting one or supporting three separators. The detection of different scripts to separate compound names without separator (as it is common in particular in Africa) is a different matter. But i am pretty sure once there is a viable way to get multilingual name display without an undesired delimiter, the local communities would not be opposed to changing that. For the moment this complexity is there to support all the common multilingual name tagging variants with equal determination.
Isn’t the preprocessed default_language data highly prone to vandalism because a single tag change can massively affect large parts of the map?
If you process the data in a simplistic way (like a process newly run on a daily basis) then yes. But for data not subject to rapid changes (languages of regions do not change from one day to the other) this is a solved problem. You have to apply some change dampening, i.e. roll out a change in tagging in the processed data only once it has proven to be stable over a longer period (like a week or a month). This is not rocket science, just a bit of hand work.
Shouldn’t other tags (like brand, operator, addresses) be subject to the same font selection logic as names?
Yes. As said, this is a proof-of-concept demonstration, not a ready-to-use product.
Nice, but where is the point? If this is not included in OSM-Carto it is extremely unlikely that it will have a substantial positive influence on mapping practice.
True. But you have to start somewhere. As said, nothing of substance has changed for the past five years. This is an attempt to provide a perspective how things can change. It is up to others to decide if they support the idea.
Real world examples:
How does this look like with real data? Here you go:
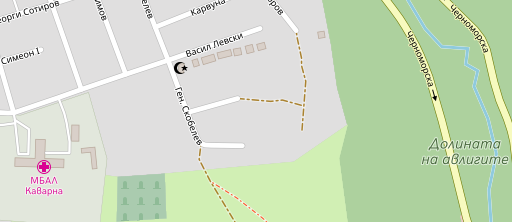
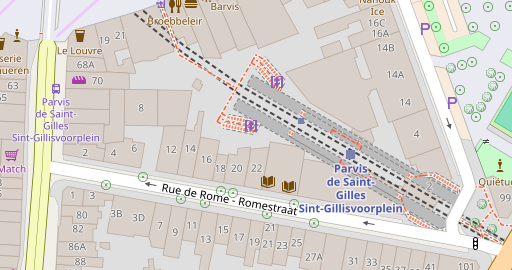
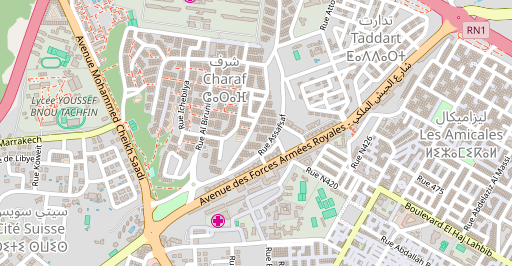
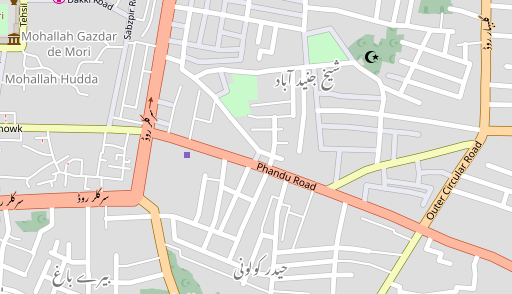
In most cases some compound labels are missing because the individual names are not in other name tags or because they are written differently in those. And you can see that in some cases the order of compound labels is different because of the logic described above.
January 23, 2023 at 23:57
Would it make sense to allow a list in *default_language* on a node? In the community forum, a case was brought forward of an administrative department, that was located in a boundary with presumably it:de locale but was in charge of a boundary presumably in a de:it locale. (As far as I understand, default_language is an ordered list.)
January 24, 2023 at 00:44
Thanks for the comment.
default_languagehas in principle been extended to potentially contain more than a single language. If you are in support of that and also think thatdefault_languagecan be tagged on individual features and not just administrative boundary relations (which is currently not consensus use) then the answer would probably be yes. But i would be a bit careful with inflationary overloading of different meanings onto that tag. If you have a primary language and want to document what commonly used secondary languages are (think of things like English in French speaking parts of Canada etc.) then a different tag (likesecondary_languages) might be more suitable. Even if there is consensus thatdefault_languageis an ordered list it is still not fully clear ifdefault_language=it;demeans: This is bilingual region with Italian and German on equal level and Italian is marginally more common or typically shown first or if it means: This is an Italian speaking region with German being also widely used but clearly secondary to Italian.Pingback: weeklyOSM 654 – weekly – semanario – hebdo – 週刊 – týdeník – Wochennotiz – 주간 – tygodnik